[Python] Beautiful Soup Post 방식을 통해 KRX 주식정보 가져오기
in DATA on Data, Python, Python_Data, Beautiful-soup, Post, Krx, Data, 주식데이터
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
KRX에서 Post 데이터 가져오기
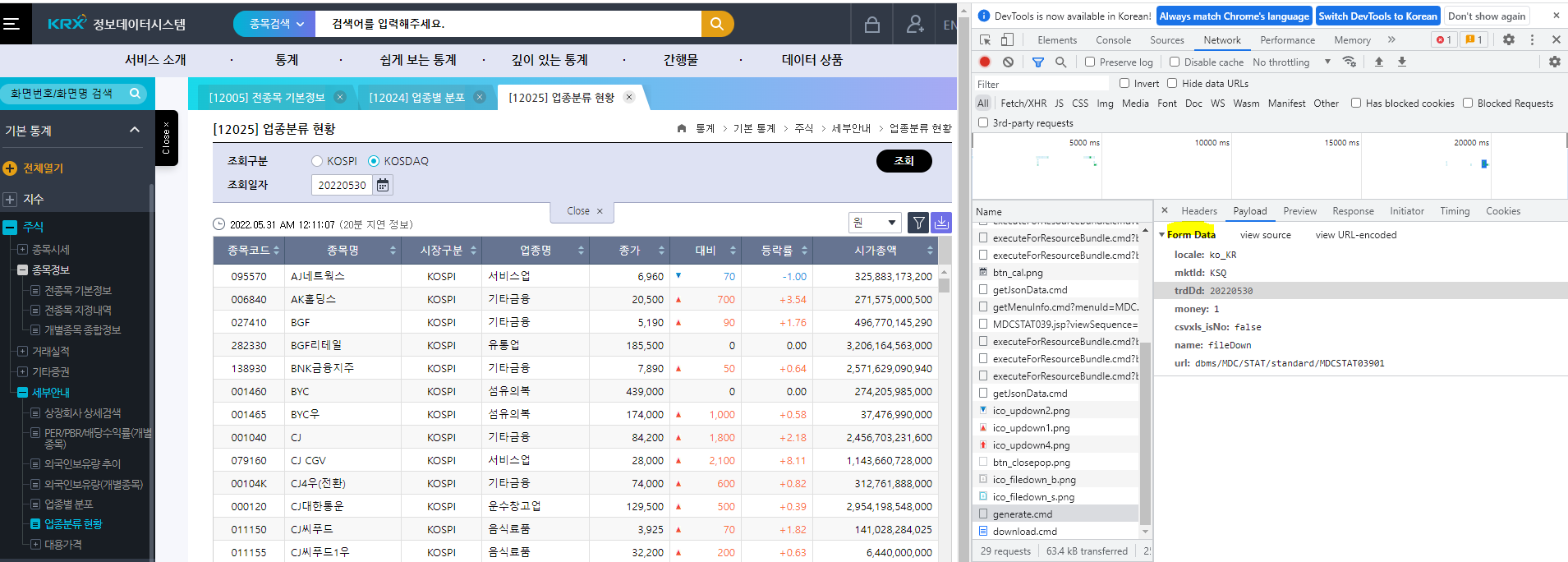
- KRX 사이트에 들어간다 (http://data.krx.co.kr/contents/MDC/MDI/mdiLoader/index.cmd?menuId=MDC0201020201)
- F12 버튼을 누르고 오른쪽 위 다운로드 버튼을 누르면 CSV, EXCEL 형식 중 무엇으로 받을지 물어본다. CSV를 선택한다.
- generated.cmd와 download.cmd 두 개가 생긴다.
- 구조는 generate.cmd에서 OTP데이터를 만들어 KRX 사이트에 전달하면, download.cmd가 실행되는 구조
- generate.cmd의 정보를 download.cmd가 받아들이면 Form Data에는 generate.cmd에서 생성한 OTP 정보가 들어가 있음
- 개발자도구에서 Payload 부분에 들어가면 Form Data가 있는데 해당 부분을 가져와서 post 정보로 구성해야함
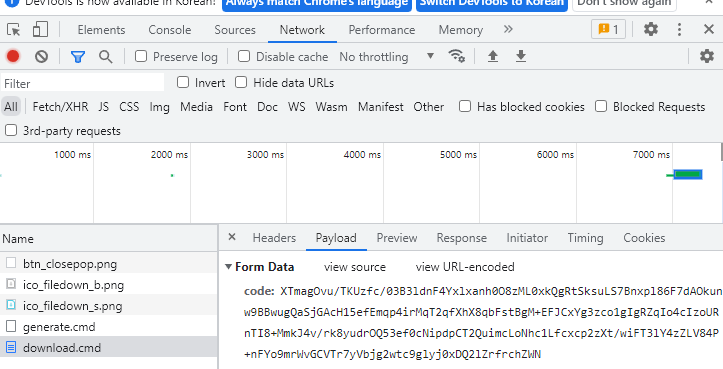
generate.cmd에서 otp 받아오기
otp_url = "http://data.krx.co.kr/comm/fileDn/GenerateOTP/generate.cmd"
data = {
"locale": "ko_KR",
"mktId": "STK", # 코스피
# "mktld" : "KSQ" # 코스닥
"trdDd": "20220530", # 가장 최근 영업일 기준으로 조회 필요
"money": "1",
"csvxls_isNo": "false",
"name": "fileDown",
"url": "dbms/MDC/STAT/standard/MDCSTAT03901"
}
response = requests.post(otp_url, data=data)
otp = bs(response.text, "html.parser")# OTP 생성
C:\python3\lib\site-packages\bs4\__init__.py:435: MarkupResemblesLocatorWarning: The input looks more like a filename than markup. You may want to open this file and pass the filehandle into Beautiful Soup.
warnings.warn(
download.cmd에서 otp 받아 데이터 생성하기
down_url = "http://data.krx.co.kr/comm/fileDn/download_csv/download.cmd"
down_res = requests.post(down_url, data= {"code" : otp}, headers={"Referer" : otp_url})
down_url을 생성- post 방식으로 데이터를 받아온다
code에는 위에서 생성한 otp를 딕셔너리 형태로 저장해준다.headers부분에는 리퍼러를 지정해준다. 리퍼러는 링크를 통해서 웹사이트를 방문할 때 남기는 흔적인데, 이게 남겨지지 않으면 서버는 이를 봇으로 인식해서 데이터를 반환하지 않는다. 따라서 header에 리퍼러를 딕셔너리형태로 넣어준다.
data = bs(down_res.content.decode("euc-kr","replace"), "html.parser") # 인코딩 깨지지 않게
str_data = data.text.split("\n")
str_data[:5]
['종목코드,종목명,시장구분,업종명,종가,대비,등락률,시가총액',
'"095570","AJ네트웍스","KOSPI","서비스업","7030","0","0.00","329160733850"',
'"006840","AK홀딩스","KOSPI","기타금융","19800","850","4.49","262301707800"',
'"027410","BGF","KOSPI","기타금융","5100","-40","-0.78","488155634100"',
'"282330","BGF리테일","KOSPI","유통업","185500","-2500","-1.33","3206164563000"']
DataFrame 만들기
# row = [x[1].replace('"','').split(",")[0] for x in str_data]
# ticker = apply(lambda a : a.replace('"',''), [x.split('","')[0] for x in str_data][1:])
ticker = [x.replace('"','') for x in [x.split('","')[0] for x in str_data[1:]]]
name = [x.replace('"','') for x in [x.split('","')[1] for x in str_data[1:]]]
market = [x.replace('"','') for x in [x.split('","')[2] for x in str_data[1:]]]
sector = [x.replace('"','') for x in [x.split('","')[3] for x in str_data[1:]]]
close = [x.replace('"','') for x in [x.split('","')[4] for x in str_data[1:]]]
updown = [x.replace('"','') for x in [x.split('","')[5] for x in str_data[1:]]]
dod = [x.replace('"','') for x in [x.split('","')[6] for x in str_data[1:]]]
total = [x.replace('"','') for x in [x.split('","')[7] for x in str_data[1:]]]
all_data = list(zip(ticker, name, market, sector, close, updown, dod, total))
- DataFrame 형식으로 만들기 위해서 전처리가 조금 필요함
- List Comprehesion을 중복 적용해서 종목코드 ~ 시가총액의 값들을 불러옴
list와zip함수를 이용해서 list들을 묶어주고 아래 코드와 같이 DataFrame 만들어주기
df = pd.DataFrame(all_data, columns = ['종목코드','종목명','시장구분','업종명','종가','대비','등락률','시가총액'])
df.sort_values("시가총액", ascending=False)
| 종목코드 | 종목명 | 시장구분 | 업종명 | 종가 | 대비 | 등락률 | 시가총액 | |
|---|---|---|---|---|---|---|---|---|
| 428 | 005930 | 삼성전자 | KOSPI | 전기전자 | 66500 | 600 | 0.91 | 396990539575000 |
| 84 | 373220 | LG에너지솔루션 | KOSPI | 전기전자 | 430500 | 0 | 0.00 | 100737000000000 |
| 150 | 000660 | SK하이닉스 | KOSPI | 전기전자 | 106000 | 3000 | 2.91 | 77168250690000 |
| 422 | 207940 | 삼성바이오로직스 | KOSPI | 의약품 | 834000 | -6000 | -0.71 | 59359116000000 |
| 429 | 005935 | 삼성전자우 | KOSPI | 전기전자 | 60100 | 300 | 0.50 | 49455490670000 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 313 | 001525 | 동양우 | KOSPI | 비금속광물 | 8050 | 70 | 0.88 | 4972734550 |
| 699 | 002787 | 진흥기업2우B | KOSPI | 건설업 | 16450 | -50 | -0.30 | 4849591600 |
| 937 | 000547 | 흥국화재2우B | KOSPI | 보험 | 27850 | 50 | 0.18 | 4277760000 |
| 310 | 001529 | 동양3우B | KOSPI | 비금속광물 | 34250 | -450 | -1.30 | 3072978500 |
| 527 | 009275 | 신원우 | KOSPI | 섬유의복 | 31000 | 0 | 0.00 | 2812940000 |
940 rows × 8 columns
- 일부 숫자값들도 문자값으로 들어갔으므로 int와 float로 교체
df["시가총액"] = df["시가총액"].astype("int64")
df["종가"] = df["종가"].astype("int64")
df["대비"] = df["대비"].astype("int64")
df["등락률"] = df["등락률"].astype("float")
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 940 entries, 0 to 939
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 종목코드 940 non-null object
1 종목명 940 non-null object
2 시장구분 940 non-null object
3 업종명 940 non-null object
4 종가 940 non-null int64
5 대비 940 non-null int64
6 등락률 940 non-null float64
7 시가총액 940 non-null int64
dtypes: float64(1), int64(3), object(4)
memory usage: 58.9+ KB
